
Published on:
November 5, 2025
Latest Update:
November 5, 2025

IT Change Management
Bring every change under control—without slowing the business. This article is for leaders who land on Serviceaide’s IT Change Management page from the broader Change Management hub and want one clear, narrative walkthrough of what modern IT change really is, why it matters now, and how the practice works when you blend ITIL with Agile, DevOps, and audit‑ready evidence. It avoids checklists and jargon‑walls; instead, it tells the journey end‑to‑end so your team can picture how change becomes repeatable, safe, and fast.
Why change management matters now
Software and infrastructure change constantly. Microservices multiply dependencies; cloud providers roll updates at their own pace; security teams tighten policies; products ship daily. When approvals live in email, schedules live in spreadsheets, and evidence lives nowhere in particular, risk sneaks in: outages, failed audits, and unexplainable drift. ITIL gives you a common language for change; Agile and DevOps give you speed. The modern practice is the bridge—standard methods, policy‑driven approvals, and verifiable proof woven directly into the way teams already work.
What we mean by “IT change” (and what we don’t)
An IT change is any addition, modification, or removal that could affect production services: code releases, database schema updates, firewall rules, identity and policy changes, Infrastructure‑as‑Code, even feature flag toggles that alter user experience. Organizational change—training, communications, stakeholder buy‑in—matters too, but this article focuses on the system side: how you assess risk, authorize safely, implement, validate, and prove what happened.
ITIL in plain language
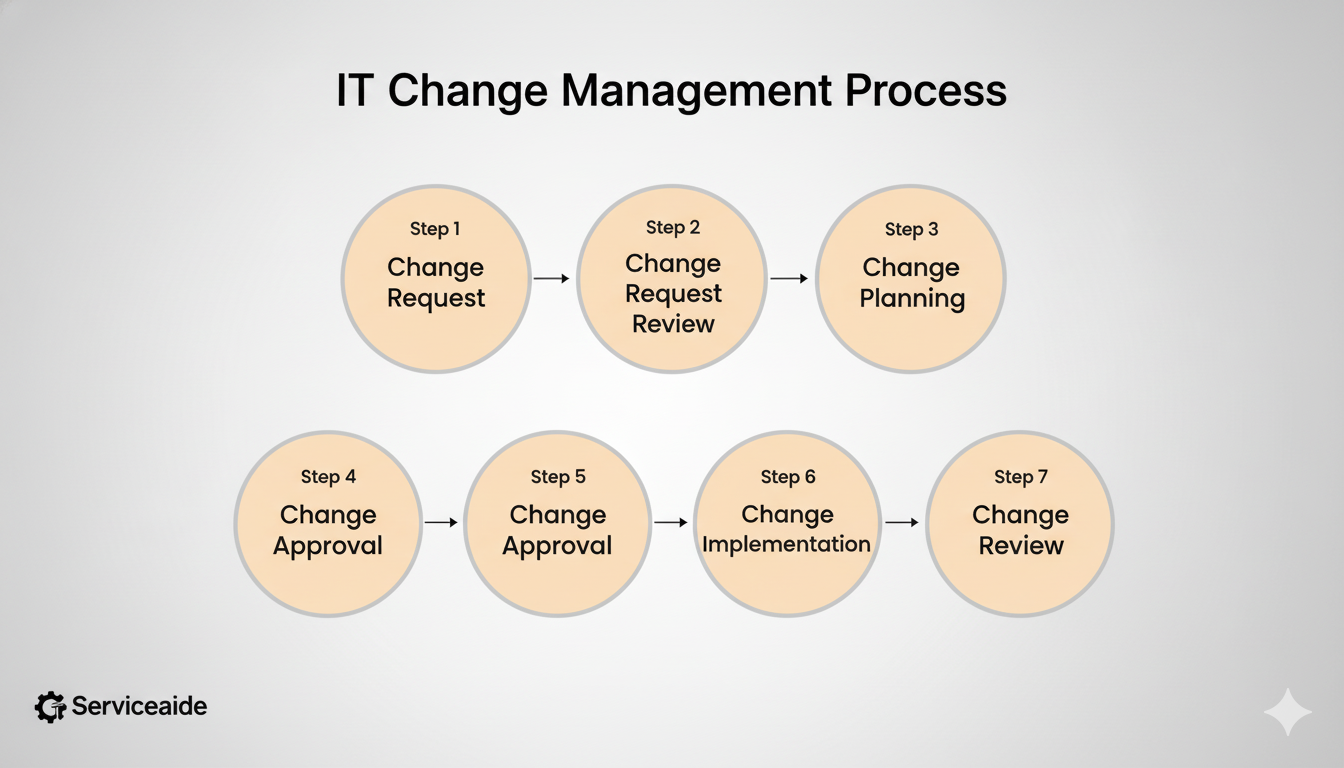
Classic ITIL (often called v3) describes a sequence that most teams recognize: someone raises a change; you assess impact and risk; you decide whether a CAB needs to review; you authorize, schedule, implement, verify, and close with a post‑implementation review. ITIL 4 updates the emphasis: less gatekeeping, more enablement. Policies and data decide when human review is necessary; automation handles the routine. You’ll see both ideas in practice because enterprises rarely live at one extreme.
ITIL v3 (story form): request → assess → (CAB?) → authorize → schedule → implement → verify/rollback → close → review
ITIL 4 (value stream): plan → approve → build/test → deploy/release → validate → review → improve
A day in the life: from idea to evidence
Picture Maya, a change manager supporting a critical payments service. A developer proposes a configuration tweak to increase throughput. As soon as the request is logged, it’s tied to the correct service and the specific configuration items in the CMDB. That link is not busywork: it’s how Maya sees upstream and downstream blast radius, who owns the service, and which environments are in scope. The system calculates risk using impact and likelihood, then adjusts for service criticality, data sensitivity, and whether this kind of change has failed before. Low risk may flow straight through on policy; higher risk might queue for a light, asynchronous CAB; truly high risk reserves a formal review.
Approval isn’t the end—it’s the beginning of traceability. The implementation plan and backout strategy are captured in the same record. When the change runs, deployment tools and scripts feed logs back into the record automatically. Observability confirms success in real time. If something goes wrong, the backout plan isn’t a paragraph; it’s executable steps that return the system to its previous snapshot. Post‑implementation, Maya closes the loop: the change record now reads like a short story auditors can follow—who asked, who approved, what changed, when, where, how it was verified, and how it would have been reversed.
Standard, normal, and emergency—without the alphabet soup
Not every change deserves a meeting. Standard changes are the repeatable, low‑risk jobs you can script and pre‑approve: rotating TLS certificates, adjusting a well‑tested autoscaling parameter, deploying a minor UI copy update. Normal changes cover everything else and scale the level of scrutiny based on risk. Emergency changes are rare by design: they exist for true incidents and security issues where waiting would cause more harm than acting. The point isn’t to reduce control; it’s to place control where it belongs—on the risk, not on the calendar.
The role of CAB (and when policy replaces it)
A CAB is useful when expert conversation changes the decision. If a proposal affects a regulated system, crosses team boundaries, or creates unusual risk, a short, focused review adds value. For routine, well‑understood work, policy is the review: templates, thresholds, and pre‑conditions encode past CAB wisdom so changes can move in hours, not weeks. Most mature programs keep multiple modes: a weekly strategic CAB for high‑stakes items, an emergency CAB for incidents, and policy‑based approvals for everything standard or low‑risk.
Where CMDB, incident, and problem fit naturally
Change without configuration context is guesswork. By linking a change to the right configuration items, the impact map becomes visible: which services consume this database, which regions depend on this API, which owners must be informed. When something breaks, incident management ties back to the change so you can see cause and effect. Problem management converts recurring pain into design: the fix becomes a standard change model rather than a one‑off hero moment.
Agile and DevOps, not either‑or
Agile teams ship small and often; DevOps automates the ship. Good change management doesn’t fight that; it reinforces it. Work items create changes only when production risk appears. Pull requests and pipelines run tests and security scans. A change gate in the pipeline checks that approvals match the risk before deploy. After the deploy, monitoring and synthetic tests post back results. Feature flags reduce blast radius and let you roll forward or back quickly. The result feels like speed because it is speed—supported by just enough ceremony at the right moment.
Work item → PR → automated tests/scans → change gate (policy or CAB) → merge → deploy → verify → close
What auditors actually want to see
Auditors don’t want binders; they want receipts. They look for identity (who asked and who approved), method (how risk and impact were assessed), execution (what exactly ran), validation (how success was measured), reversibility (how you would have rolled back), and retention (that the evidence will still exist next year). When these artifacts are captured by the system of record and linked to deployments and configuration, an audit becomes a demonstration rather than an excavation.
Common failure patterns and how modern programs avoid them
Two anti‑patterns show up everywhere. First, sending every change to CAB turns review into theater; important risk hides in the noise. Second, treating the CMDB as paperwork makes it stale; if it doesn’t help with impact analysis, nobody uses it. Policy‑based approvals and automated discovery fix both: let low‑risk work flow by rule, and make configuration data the source of answers people actually need. Emergency changes shrinking over time is a healthy sign; a growing catalog of standard changes is another.
If you’re just starting—or starting over
In the first month, publish a clear policy, link every change to at least one configuration item, and adopt a simple risk model you can explain in a sentence. Identify a handful of standard changes you perform often and script them well enough to pre‑approve. Wire your deployment tools and monitors to attach logs and results automatically so evidence appears without human effort. Hold short, honest post‑implementation reviews and convert recurring fixes into standard models. You’ll feel the program getting lighter and stronger at the same time.
How Serviceaide fits
Serviceaide turns this narrative into software. Risk scoring and routing happen as soon as a request lands. Policy‑based approvals replace busywork; virtual and emergency CABs are there when judgment matters. Every record links to the right services and configuration items. Pipelines enforce change gates so nothing risky deploys without the right authorization. Logs, tests, and monitoring results attach themselves; the audit trail builds in the background. You can run Serviceaide as your primary system or lay it on top of existing tools to standardize change and centralize proof.
Where to go next
This Awareness piece was meant to give you the big picture without drowning you in bullets. If the why and the what make sense, the next step is the how. In Stage 2: Consideration, we’ll show concrete execution patterns: risk policies you can adopt as‑is, lightweight CAB models, CI/CD gate designs, and the way change interacts with problem, incident, and configuration in day‑to‑day operations. When you’re ready to see it live, book a walkthrough and bring a recent change record—we’ll map it to a modern flow so you can compare outcomes side by side.
Latest Insight

June 12, 2026
The Hidden Link Between Knowledge Management and Change Management Success

June 10, 2026
What Auditors Are REALLY Looking For in your CMDB

April 22, 2026





.svg "LinkedIn")
.svg "YouTube")